How I Used Deep Learning To Train A Chatbot To Talk Like Me (Sorta) Can you see the resemblance? Read More
Applying Machine Learning To March Madness The hottest topic in tech + the most exciting event in sports Read More
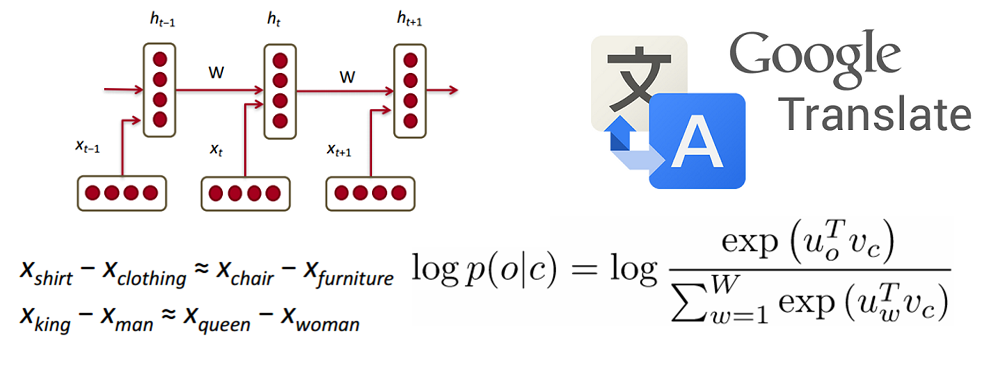
Deep Learning Research Review Week 3: Natural Language Processing An introduction to applying Deep Learning to Natural Language Processing tasks Read More
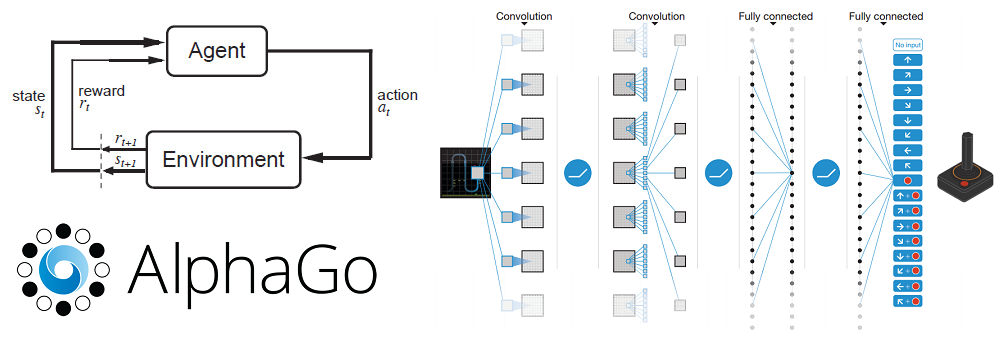
Deep Learning Research Review Week 2: Reinforcement Learning An introduction to Reinforcement Learning and a look of two of the most important papers Read More
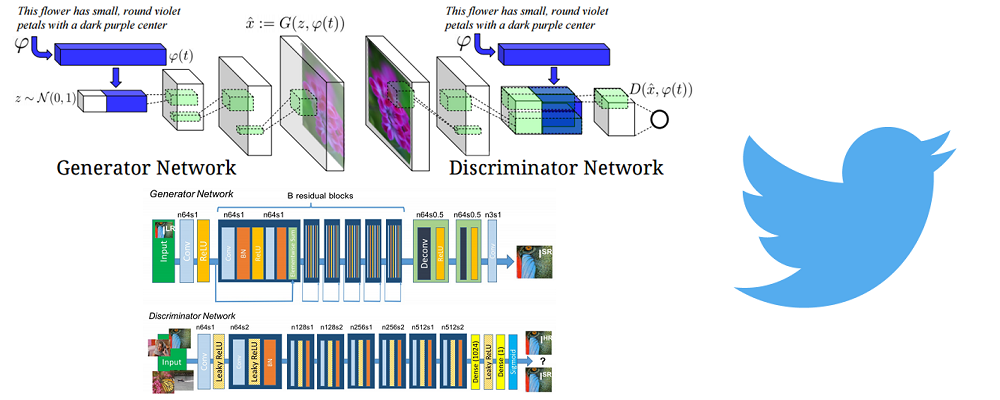
Deep Learning Research Review Week 1: Generative Adversarial Nets 3 recent papers that are built on generative adversarial nets Read More
Analyzing The Papers Behind Facebook's Computer Vision Approach How the world's most popular social networking site uses CNNs Read More
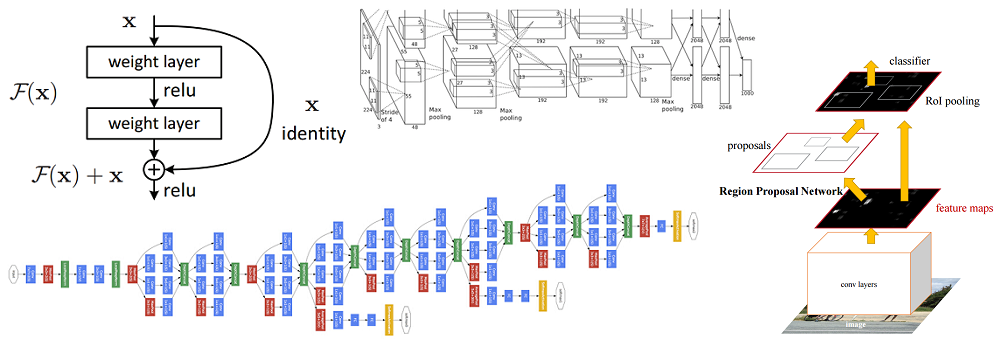
The 9 Deep Learning Papers You Need To Know About (Understanding CNNs Part 3) Summarizing and explaining the most impactful CNN papers over the last 5 years Read More
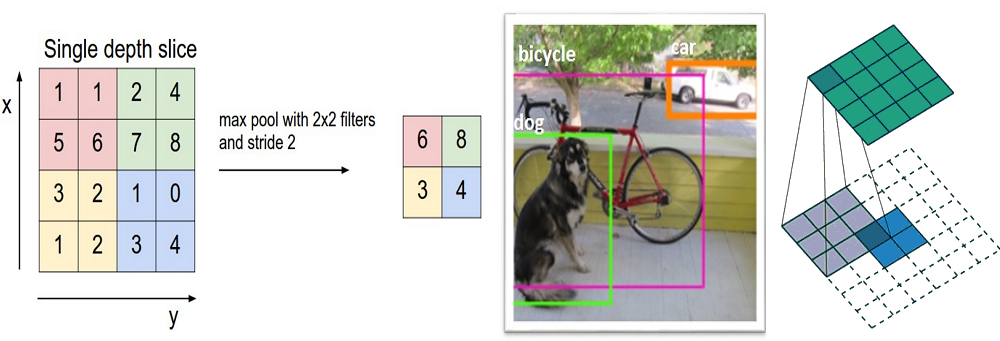
A Beginner's Guide To Understanding Convolutional Neural Networks Part 2 ReLUs, Pooling, Dropout...(aka The Fun Stuff) Read More
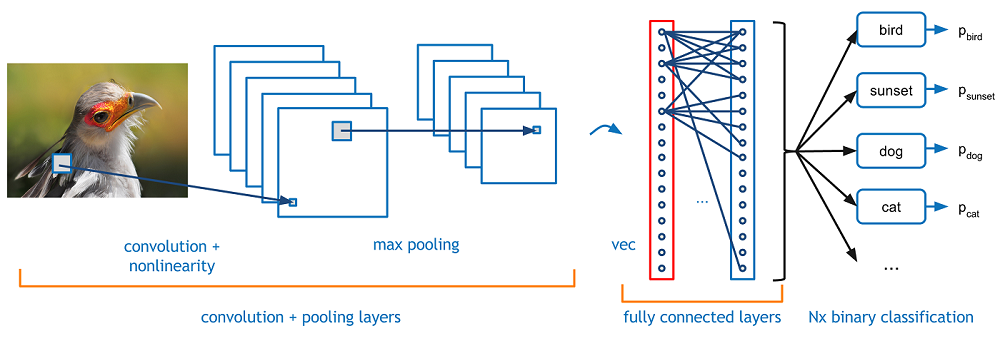
A Beginner's Guide To Understanding Convolutional Neural Networks Don't worry, it's easier than it looks Read More